RVO-MIS: Robust Visual Odometry for Minimally Invasive Surgery



 Paper
Code
Paper
Code
Abstract
Visual odometry (VO) in minimally invasive surgery (MIS) scenarios plays a crucial role in current and future endoscopic surgical intervention assistance systems. However, MIS environments pose severely challenging situations for typical VO algorithms due to textureless scenes, the presence of surgical instruments, light reflections, flowing blood and organ deformation, etc. Classic VO methods adopt a smooth motion prior to generate an initial guess for camera pose and then refine it through minimizing reprojection errors. Recent deep learning methods incorporate learned depths and estimate camera poses through minimizing photometric residuals. These approaches, however, lack robustness in estimation due to abrupt motion change and unpredictable illumination changes commonly seen in MIS environments. In this paper, we present RVO-MIS, a robust VO framework in MIS by first integrating SIFT and LightGlue for reliable feature correspondences, and then solving a sequence of absolute camera poses under a M-estimator sample consensus (MSAC) scheme. By advocating the absolute-pose-first formulation to prioritize geometric consistency and robustness, our approach decouples the camera motion tracking from smooth motion prior, photometric consistency, learned depths, etc. Through evaluations on the SCARED and EndoSLAM datasets, RVO-MIS demonstrates consistently accurate camera pose estimations. In challenging MIS situations where many methods fail or become inaccurate, RVO-MIS excels in both camera trajectory completion rate and accuracy. Code is publicly available at https://github.com/vsi-lab/RVOMIS.git.
Overall framework of RVO-MIS

Results
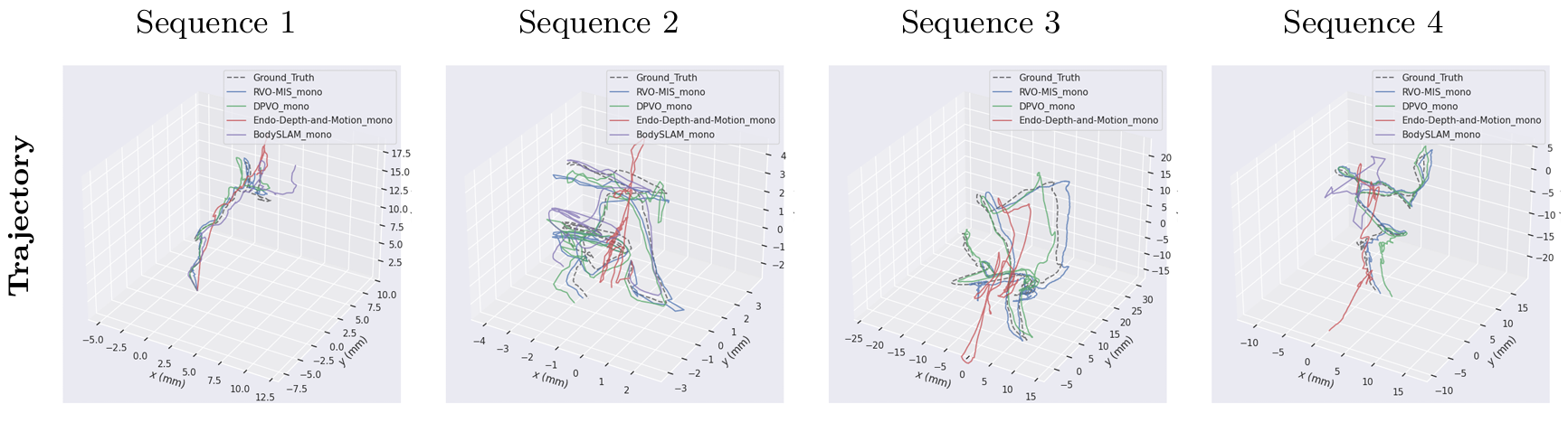
Trajectories (origin alignment) comparison for the representative sequences in the SCARED dataset.
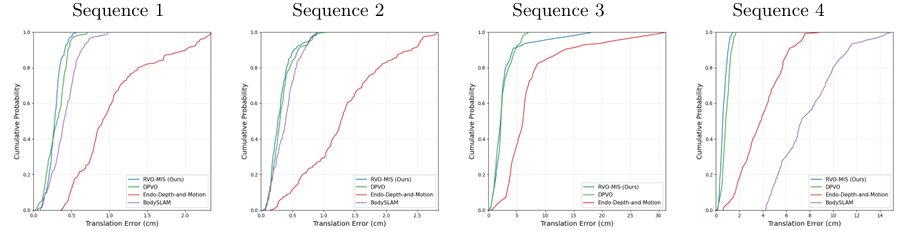
CDF of the translation ATE across SCARED representative sequences.
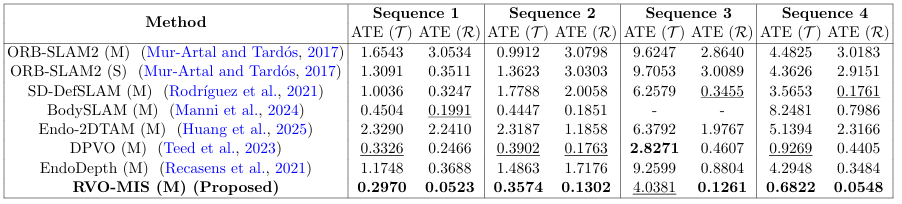
ATE (RMSE) using global alignment on four representative sequences from the SCARED dataset.
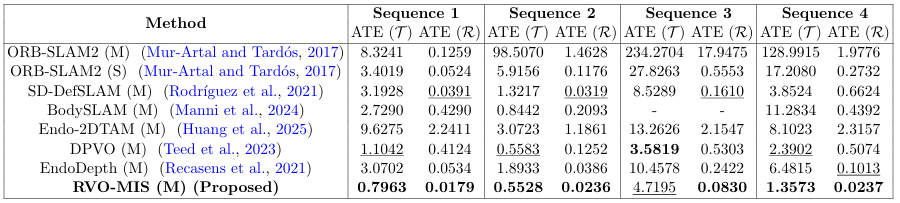
ATE (RMSE) using origin alignment on four representative sequences from the SCARED dataset.
BibTeX
@inproceedings{wang2026rvomis,
title={{RVO}-{MIS}: Robust Visual Odometry for Minimally Invasive Surgery},
author={Zhuo Wang and Chiang-Heng Chien and Eungjoo Lee},
booktitle={Medical Imaging with Deep Learning},
year={2026},
url={https://openreview.net/forum?id=Gr3W3c5tz9}
}